Normalization:-
There are present multiple ways to represents your data. One of the way is in a Normalized way. Normalized way means, dividing up the data in to multiple collections. Another important aspect is that document of one collection can be referenced by the multiple documents of the different collections. That means there present some kind of relationships between these documents.
In the RDBMS we always prefer to store data in a normalized form and keep the relationships between them with the help of the constraints (primary ley and foreign key relationships). Lets look the below mentioned example:-
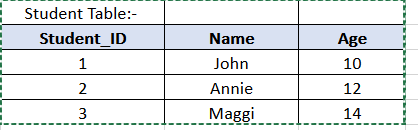
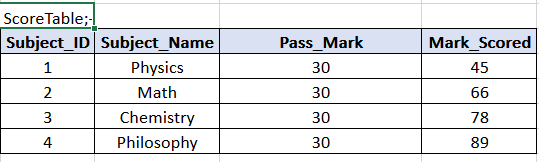
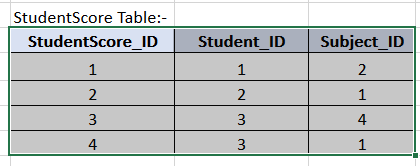
So here the data in these three tables are stored in a highly normalized form. Student_ID column of the Student table is referenced by the Student_id column of the StudentScore table. And the Subject_id column of the subject table is referenced by the subject_id column of th StudentScore table. In general in RDBMS we always try to store the data in a normalised form as mentioned above.
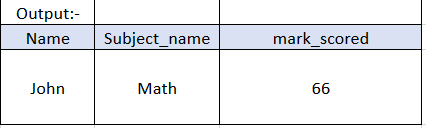
Now what is the subject name and the marks scored by John?
------SQL QUERY:-
Select student.name,score.subject_name, score.mark_scored from Student , StudentScore , Score where student.student_id=studentscore.student_id
and studentscore.subjec_tid = score.subject_id
and student.name = 'John';
Now in the world of Mongo DB, the collection is equivalent to table in the SQL world and also the documents are equivalent to columns in the SQL world. So the above similar Data Model we can create in Mongo DB as below:-
<<<Creation Of Student collection:->>>
>>try{db.Student.insertMany([{"Student_ID" : 1 , "Name" : "John" , "Age" : 10}, { "Student_ID" : 2 , "Name" : "Annie" , "Age" : 12}, { "Student_ID" : 3 , "Name" : "Maggie" , "Age" : 14}])} catch(e) {print(e)}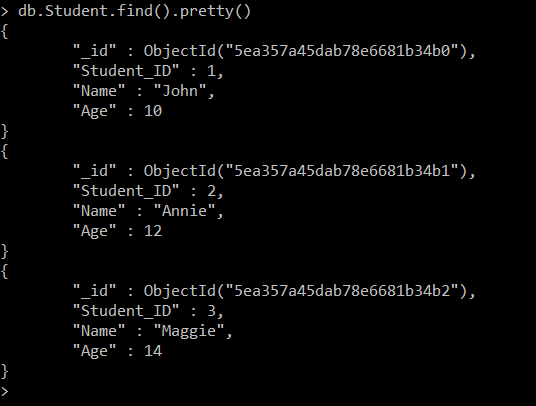
So the structure of the Student collection is same as that of the Student table in sql database. Now we will create other two collections with similar structure as that of SQL(RDBMS) database.
<<<Code to create Score collectio>>>
>db.Score.insertMany([{"Subject_ID" : 1 , "Subject_Name" : "Physics" , "Pass_Mark" : 30 , "Mark_Scored" : 45}, {"Subject_ID" : 2, "Subject_Name":"Math","Pass_Mark":30,"Mark_Scored":66}, {"Subject_ID" : 3 , "Subject_Name": "Chemistry" , "Pass_Mark" : 30,"Mark_Scored": 78}, {"Subject_ID" : 4 , "Subject_Name":"Philosophy","Pass_Mark":30,"Mark_Scored":89}])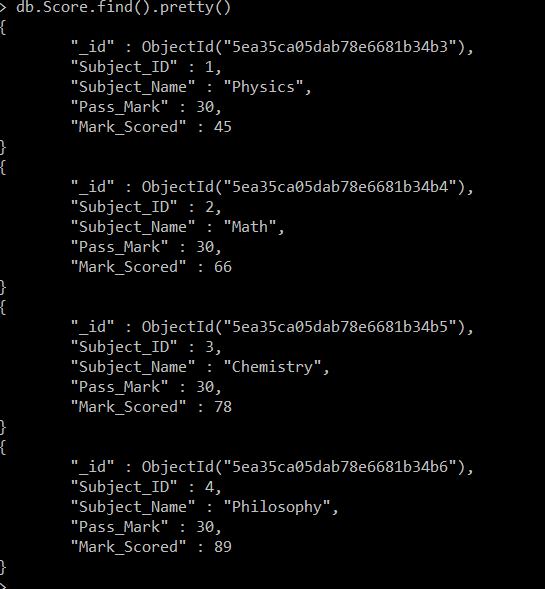
> db.StudentScore.insertMany([{StudentScore_ID : 1 , " Student_ID" : ObjectId("5ea357a45dab78e6681b34b0"), "Subject_ID" : ObjectId("5ea35ca05dab78e6681b34b4")}, {"StudentScore_ID" : 2 , "Student_id": ObjectId("5ea357a45dab78e6681b34b1"),"Subject_ID":ObjectId("5ea35ca05dab78e6681b34b3")}, {"StudentScore_ID":3,"Student_ID":ObjectId("5ea357a45dab78e6681b34b2"),"Subject_ID":ObjectId("5ea35ca05dab78e6681b34b6")}, {"StudentScore_ID":4,"Student_ID": ObjectId("5ea357a45dab78e6681b34b2"),"Subject_ID":ObjectId("5ea35ca05dab78e6681b34b3")}]) 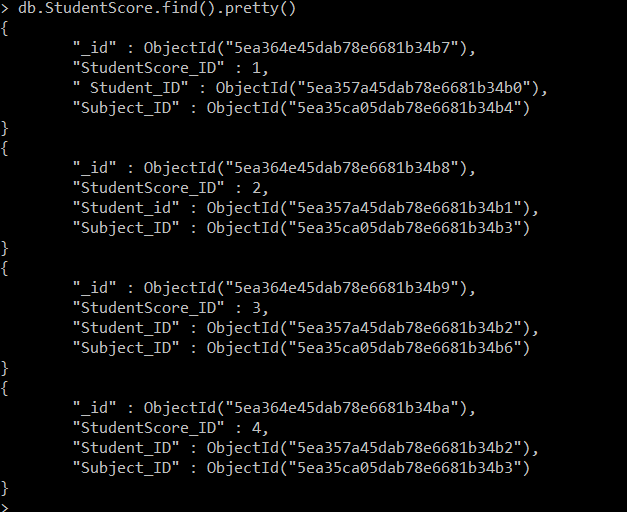
Now to find the subject’s name and the score of the ‘John’ we can use the below mentioned query:-
db.StudentScore.aggregate([{$match:{Student_ID:1}},{$project:{"_id":0}},{$lookup:{"from":"Student",localField:"Student_ID",foreignField:"Student_ID",as:"Studentrole"}},{$project:{"Student_ID":0}},{$unwind:"$Studentrole"},{$lookup:{from:"Score",localField:"Subject_ID",foreignField:"Subject_ID",as:"Score_details"}} ,{$unwind: "$Score_details"},{$project:{"_id":0,"Studentrole.Name":1,"Score_details.Subject_Name":1,"Score_details.Mark_Scored":1}} ]).pretty()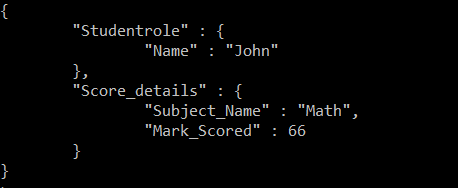
So in the above example the concept of Normalisation is explained. Basically here we have distributed the data in a small set of collections.
De-Normalization:-
De-Normalisation is exactly opposite of normalisation. Here data is kept inside one collection rather than distributing it or rather within a single document inside the Mongo Db collection. So it may happen that we have to store same documents with same value multiple time. AS in the above cases, there are separate two tables which are storing the student details and corresponding their marks. Now in the below example one denormalized collection will be created where all the details will be stored within a single collection.
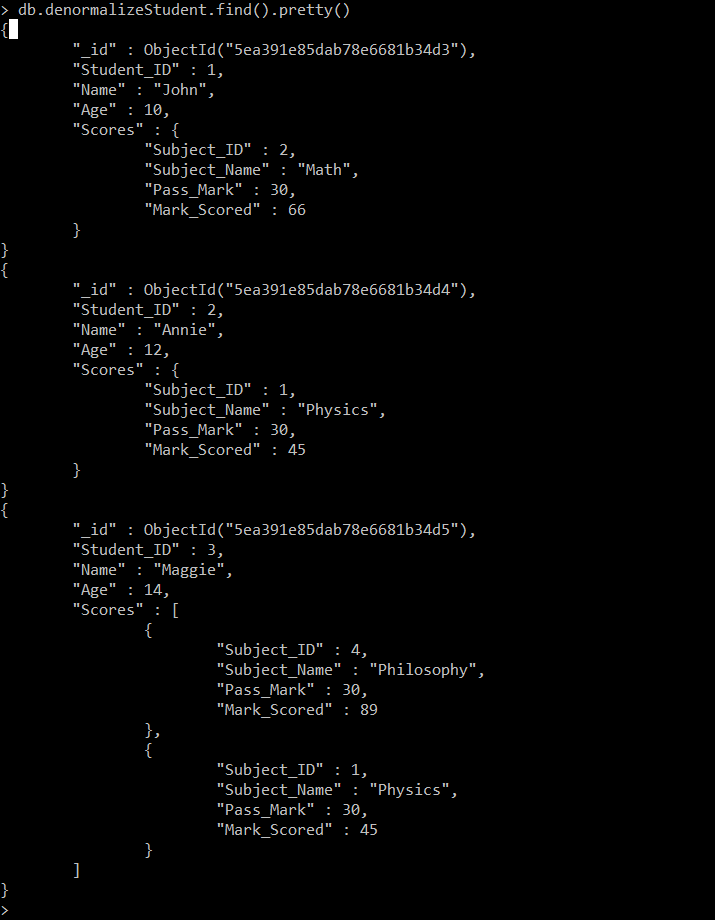
In the above case, one denormalized collection is created here where for each document the corresponding scores are mentioned in a nested way.
Now again if again we need to find the mark john obtained in math, then the query will be like :-
db.denormalizeStudent.find({"Name":"John"},{_id : 0 , Name : 1, "Scores.Subject_Name": 1 ,"Scores.Pass_Mark" : 1}).pretty()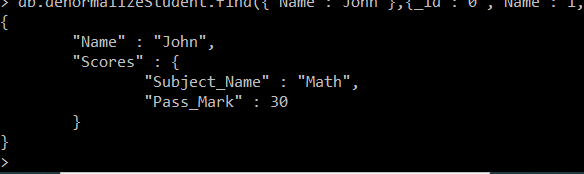
This is the true power of de-normalization and no-sql databases.
De-Normalization vs Normalization:-
So from the above two examples and relationship between the Student and the Scores table, it’s quite clear that the de-normalize table always is very much efficient for the reading purpose. Just in the preceding example, only one line query is sufficient to fetch the desired result. But Normalize table is very much inefficient for such reading purpose. Because we have to read from the disk for the three times for the preceding normalized example, which is very poor from the performance point of view.
And another aspect, for writing purpose Normalized data model is always good because here, write is required for only one time. As in the case of preceding example for de-normalized table, the same data is present multiple time, so we have to update that subject for multiple time. So that is a drawback for de-normalized data model.
So when the design will be made, we have to consider whether the application is going to be a writing major or reading major application and according to that we have to design our data model.